数据工程发现代漏洞的一个重要方法。 Fabs博士的博士论文就是通过发现代码中的pattern来进行漏洞挖掘(从代码问题时尚)。在传统方法不能够很好地处理的瓶颈问题上,在代码上使用数据工程发现facts不失是一个好的方法。
数据工程
数据工程大致分为三个阶段: 数据收集、 特征工程、模型训练。 针对数据,我们要做的大致有: - 从哪获得数据(数据来源):数据收集 - 数据中的噪声大(数据内容): 数据清理 - 数据不是模型想要的格式(数据格式): 数据变换 - 数据训练比较难(数据效果): 特征工程
数据收集(Data Collection)
数据收集的目标是构成目标数据集
针对目标系统,数据的收集大致分为:获取数据、标注数据、数据质量优化。 看一张总图:
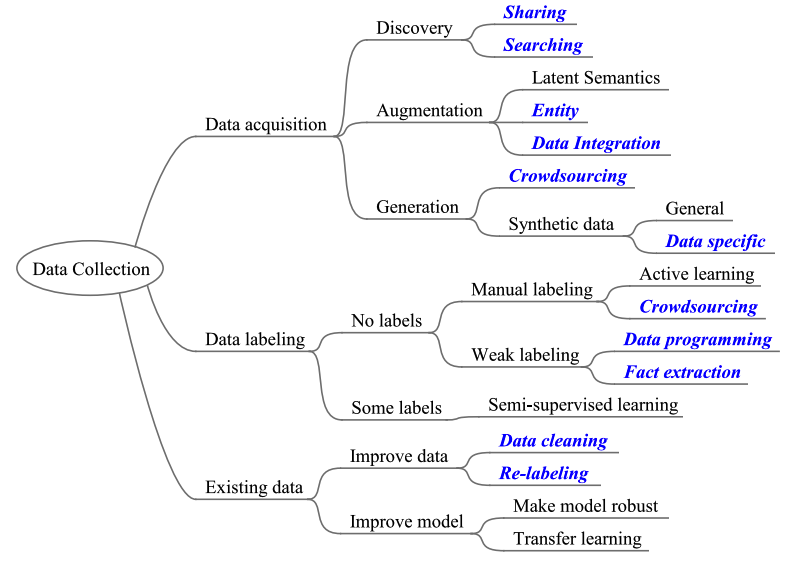
paper给出的一个分析流程:

先从section2
获取数据
从流程上将就是section2中的内容回答三个问题: - Have enough data? 有足够数据进入下一步标注 - Are there external datasets? 如果有差不多的数据集就去搜集并修改 - Have data generation method? 想办法生成数据。
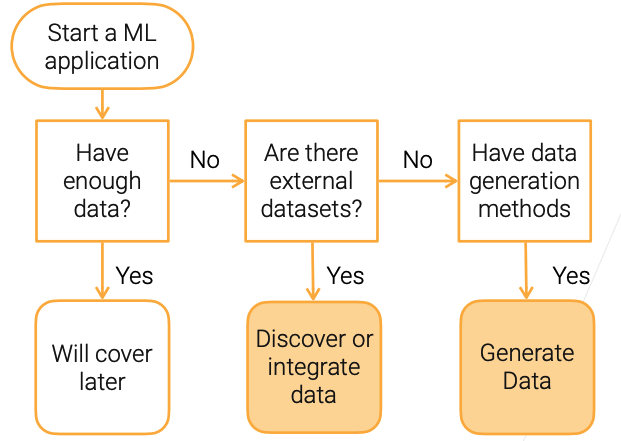
从三个角度的技术分析:
Data Discovery: 从外部获取已有数据集,方法
Data Discovery 通常有两步: 1.找已经共享标注好的数据集(Data Sharing),可以去许多的共享平台(如DataHub, kaggle)寻找之前工作整理好的数据集。也可以去CKAN, Quandl, DataMarket等购买。Google Fusion Tables也是一个数据云端管理整合平台,也可以去寻找。
- Data Searching: 如果在以上这些平台没有找到你想要的数据集,就要自己去寻找了, data lakes的出现使得data searching普遍起来。