0x00 层次聚类描述
- 首把每一个样本点看作是一个cluster, 一开始有k个cluster
- 根据算法,聚合距离最近的两个cluster,形成k-1个cluster
- 循环直至一个最大的cluster形成
- 形成一张树状图区分不同的clusters
0x02 准备数据集
命名规则
- X - 实验样本
- n - 样本数量
- m - 样本特征数量
- Z - 集群关系数组
- k - 集群数量
生成实验样本
矩阵X.shape == (n, m),现在我有十个随机点:
1 | import numpy as np |
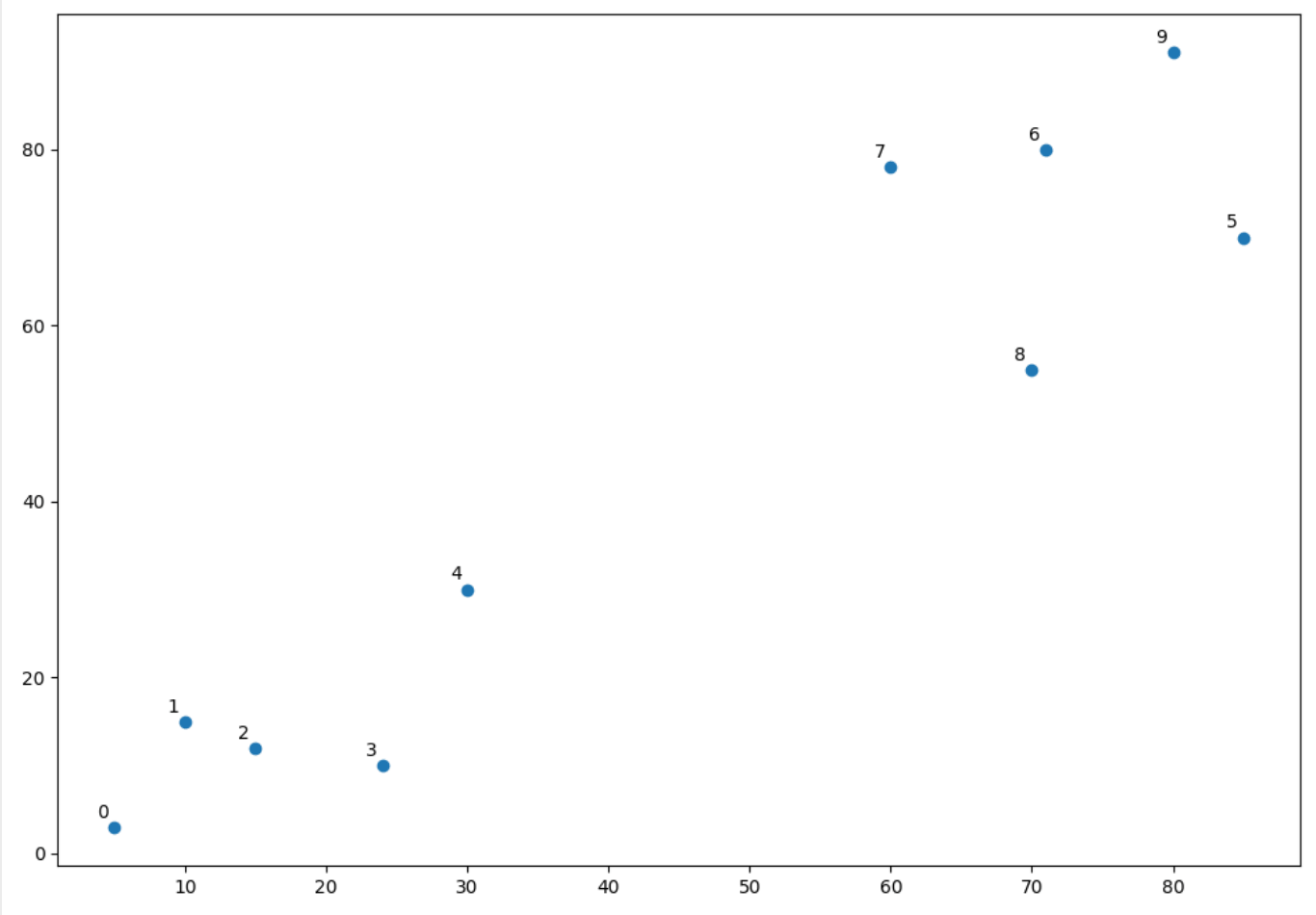
0x02 进行层次聚类
1 | Z = linkage(X, method='ward') #average, single, complete... |
method选择一个 距离算法。
1 | import numpy as np |
打印粗来:
1 | [[ 1. 2. 5.83095189 2. ] |
每一行是[idx, idx2, dist, sample_count]可以看到是本来, 第一行就是对应层次聚类的第一步, 每一个点作为一个cluster, 其中1号点和2号点是聚类最近,为5.83...,于是这两个点在此步骤聚成了一个cluster, 有两个样本点。现在有k-1个cluster。然后第二步...。
看到第3步中,开始出现9号以外的点。此算法中,任何idx>=len(X)的下标指向Z[idx-len(X)]中建立的集群。
也就是说,10代表着第Z[10-10]也就是Z[0]第一步聚成的cluster与3进行合并。也就是X[[1,2,3]]
1 | print X[[1,2,3]] |
单看他们的坐标点应该是挺近,看图:
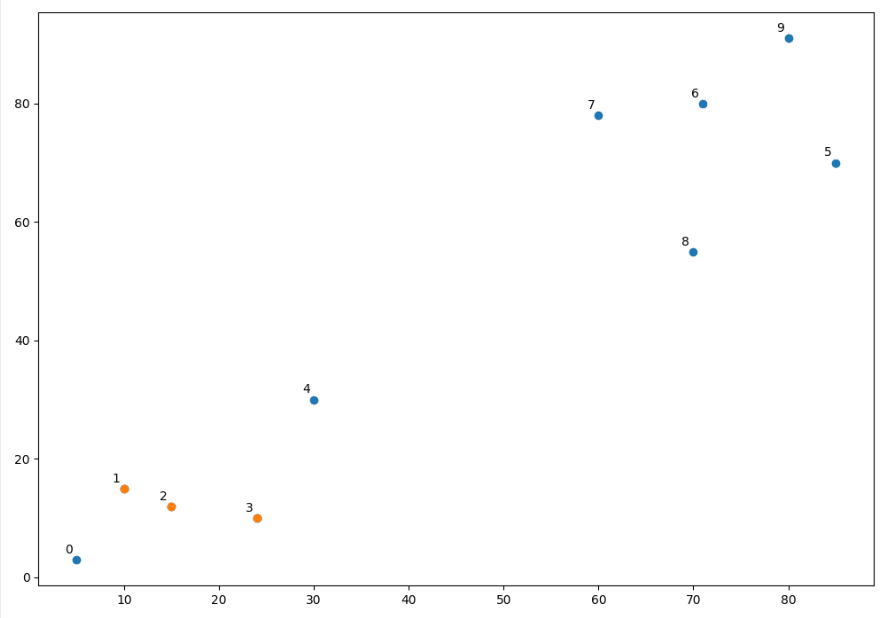
挺近...
代码:
1 | import numpy as np |
0x03 树状结构图(Dendrograms)
1 | import numpy as np |
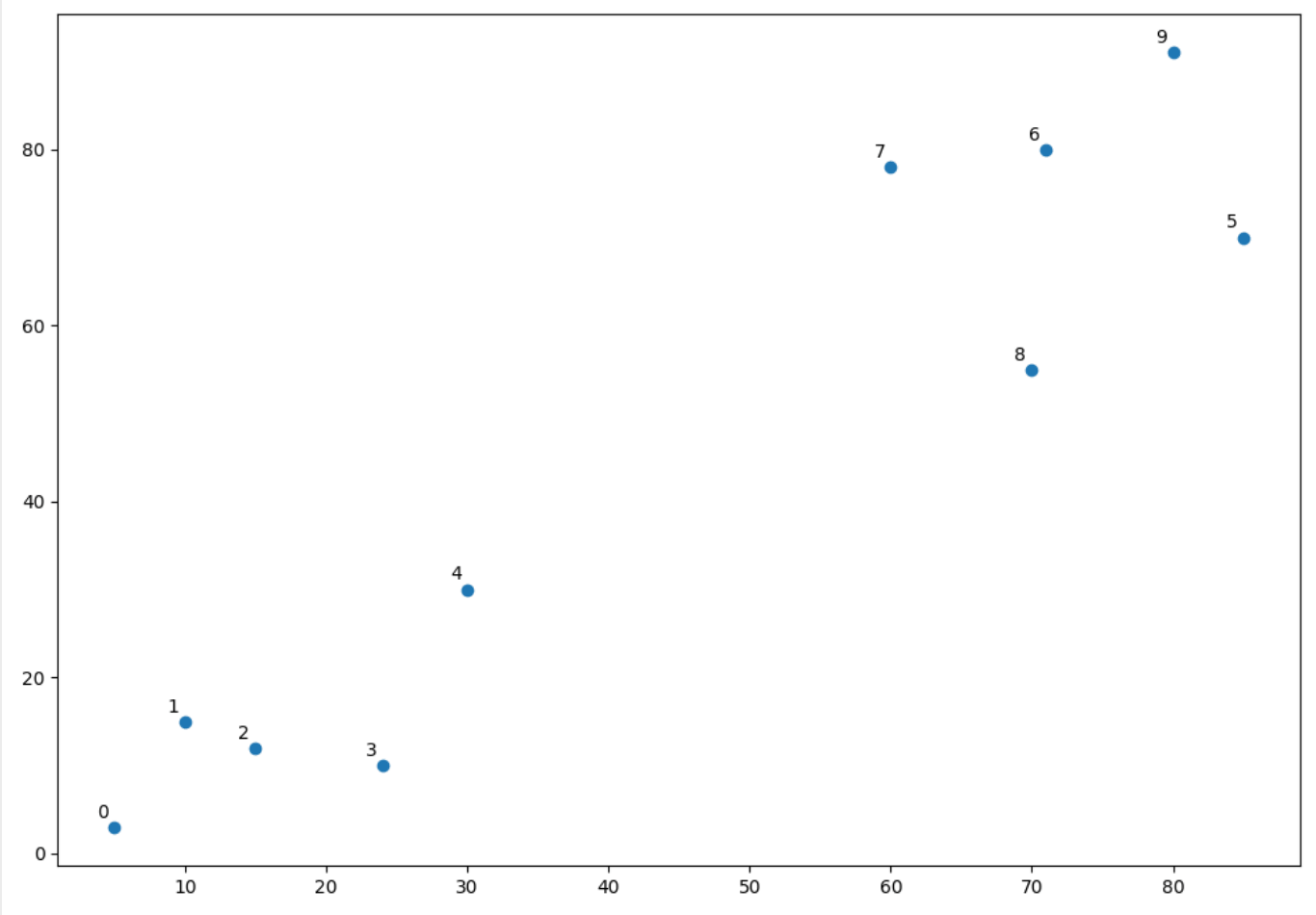
对就是这个图,让我们先,从下往上捋一捋。横坐标就是特征嘛,纵坐标看那个连接位置,就是他们聚在一起时候的值,这里好像根据的是欧几里得距离...再看我们聚类时的第一步:
1 | [ 1. 2. 5.83095189 2. ] |
所以说第1,2个点聚的最低,聚集起来的位置大概是5.8...。依次向上,最终聚成一个cluster。